Hi there, I'm Joe Tran
A
Self-driven, quick learner and passionate data scientist with a curious mind who enjoys solving complex and challenging real-world data problems.
Ex-Google Intern
About
Passionate Data Scientist with a focus on crafting exceptional user experiences through data-driven recommendations and A/B testing. With a background in developing innovative recommendation systems, I thrive on leveraging data to optimize user engagement and drive business impact. My expertise lies in designing and executing rigorous A/B tests to validate hypotheses and make informed decisions, propelling products to new heights. Additionally, I have demonstrated leadership skills as I have successfully led an agile team in building impactful products.
I also write about data science and data analytics on Medium blog during my free time.
- Advanced: Python, Tensorflow, MySQL, PostgreSQL, Tableau
- Intermediate: R, AWS SageMaker, Redshift, S3
- Familiar: HTML5/CSS3, JavaScript, React, Node.js, Express, MongoDB, PowerBI
- NLP: Word2Vec, GloVe, BERT, Seq2Seq, LSTM
- AutoML: H2O, PyCaret, AutoKeras, Auto-SKlearn, TPOT
- Others: A/B testing, Experimental Design, ETL, Text Mining, Customer Attrition Modelling
Looking for an opportunity to continue growing myself and expand my knowledge in working with analytic and end-to-end ML projects, building analysis pipelines to provide insights at scale.
Major Expertise
AB Testing:
Proficient in designing and executing A/B tests to optimize product features, user experience, and marketing strategies.
Proficient in interpreting A/B test results with a keen focus on statistical significance and practical significance, guiding stakeholders towards impactful and reliable conclusions.
Presented A/B test findings in clear and concise formats, facilitating decision-making for stakeholders at all levels of the organization.
NLP:
Proficient in leveraging state-of-the-art NLP techniques and algorithms to extract meaningful insights from unstructured text data. Skilled in applying methods such as Latent Dirichlet Allocation (LDA), GPT-3.5, and BERT to perform topic modeling, sentiment analysis, and text classification tasks.
Proficient in applying Semantic matching and similarity metrics to compare and match similar texts, enhancing information retrieval and text matching processes.
Expertise in fine-tuning pre-trained language models like GPT-3.5 and BERT for domain-specific tasks. Proficient in adapting these models to perform specialized text analysis, achieving superior performance on custom datasets.
Experience
- Conducted extensive research on state-of-the-art NLP algorithms and methodologies, resulting in the adoption of GPT-3.5 for topic modeling and text generation.
- Developed and fine-tuned customized language models for domain-specific tasks, resulting in a 15% improvement in text classification accuracy.
- Employed advanced Tableau functionalities to automate data visualization, resulting in accelerated data analysis and streamlined report generation.
- Utilized LDA and Word2Vec techniques to uncover latent themes and relationships in large-scale text corpora, facilitating the generation of valuable insights.
- Developed a text similarity matching system using semantic embeddings, resulting in a 20% reduction in text retrieval time for the university's knowledge base.
- Tools: Python, Tableau, NLP, GPT

- Built a recommendation engine in Python utilizing past order history, successfully deploying it to production on Heroku, which yielded an impressive 25% increase in Average Order Value (AOV).
- Designed and implemented a customer attrition random forest model to identify potential churners and root causes, effectively reducing the churn rate by 7%
- Used tools such as AWS SageMaker (Python) to deploy trained models into production environment with minimal codes required by the developers
- Engineered a robust web crawler using Scrapy, Beautiful Soup, and Python to gather training data for text classification models, enhancing data accessibility and ensuring accurate model performance
- Collaborated closely with the marketing team, employing the RFM model to predict customer retention, resulting in a notable 5% improvement in overall customer retention rates.
- Developed an intuitive web-app utilizing Streamlit and Python on AWS, providing real-time visualizations of cohort retention and payback ratios, effectively reducing the time spent on daily report generation by an impressive 35%
- Led a highly skilled product analytic team of 3, devising and executing impactful A/B tests to optimize product features and development, contributing to enhanced user experience and overall product performance
- Performed sentiment analysis using logistic regression and NLTK to identify the customers’ painpoints, hence improving the CSAT score by 43%
- Skills: A/B Testing · Experimental Design · Product Management · Python · SQL · NLP · Predictive Modelling · Web Development · Stakeholder Management · AWS
- Spearheaded the development of robust AB testing methodologies to analyze and optimize Google ad performance, enabling data-driven decision-making and achieving higher click-through rates and conversion rates
- Crafted and deployed a high-precision k-means clustering model to empower the marketing team in identifying and segmenting users for targeted advertising campaigns. This strategic implementation led to increased customer engagement and improved marketing ROI
- Played a pivotal role in establishing an end-to-end ML pipeline, encompassing data ingestion, feature engineering, model training, and deployment. Leveraging the power of Google Cloud Platform, I gained hands-on experience in managing and scaling machine learning workflows efficiently.
- Skills: Python · Flask · Keras · Tensorflow
- Transformed text translation capabilities by implementing advanced LSTM algorithm, resulting in significantly enhanced accuracy and fluency.
- Conducted various ad-hoc text-mining endeavors, leveraging NLP techniques to analyze and derive valuable insights from diverse news articles.
- Evaluated the impact of innovative teaching techniques on student performance by analyzing and interpreting survey/questionnaire data, providing actionable recommendations to optimize educational strategies.
- Tools: Python, R, ggplot, matplotlib, pandas, NLP
Projects

Classify sentiments of customer reviews using NLP to provide feedback for the business
- Tools: NTLK, Python, AWS SageMaker, Scrapy
- Scraped the data from google reviews with Scrapy and Python
- Used NTLK and logistic regression to classify positive and negative feedback, deployed the model to production using AWS Sagemaker
- Presented the findings to key stakeholders, including BOD and investors

A streamlit app that identify who most likely will churn
- Tools: Streamlit, Python, Heroku
- Model used: Random Forest Classifier
- Improved the model accuracy from 83% to 89% through feature engineering and regularisation techniques
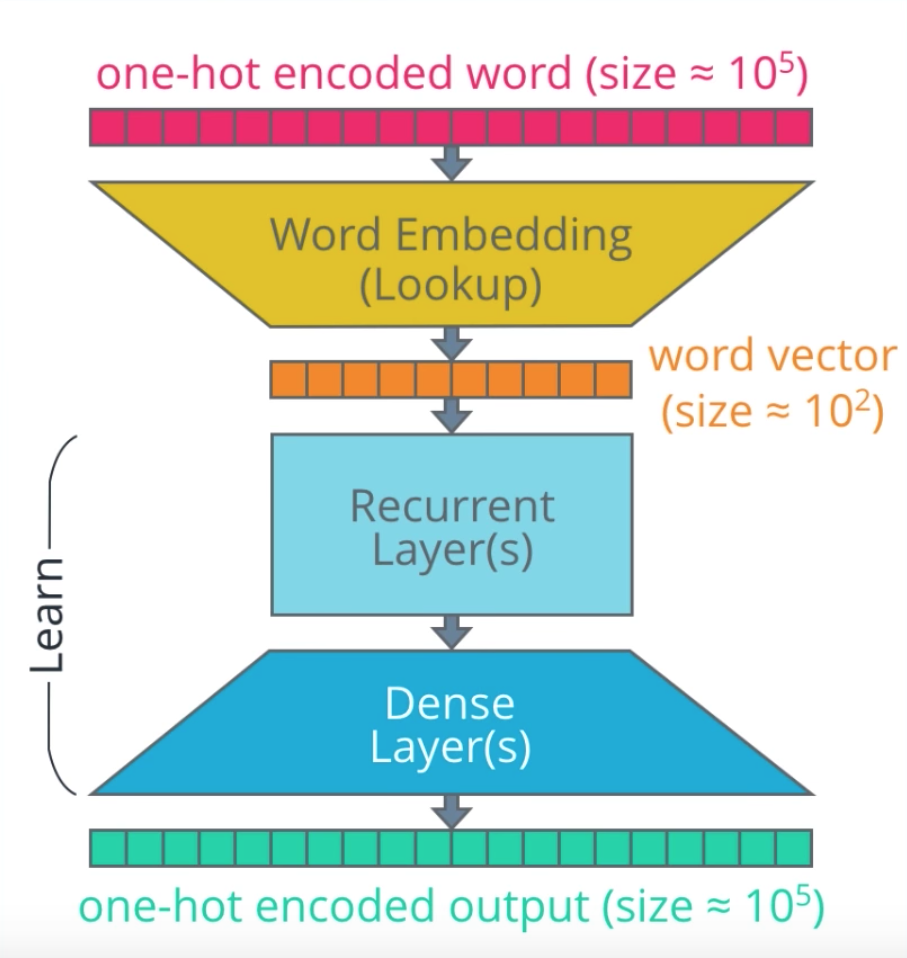
An interactive Flask app that translates Korean, Vietnamese into English and vice versa.
- Tools:Python, Flask
- Translate text using Seq2seq network

A model that generates the most relevants products of the given input product.
- Used Cosine similarity as a metric to find the most relevant products to recommend to the customers.
- Built the front-end with Flask (Python) and deployed on Heroku for internal usage
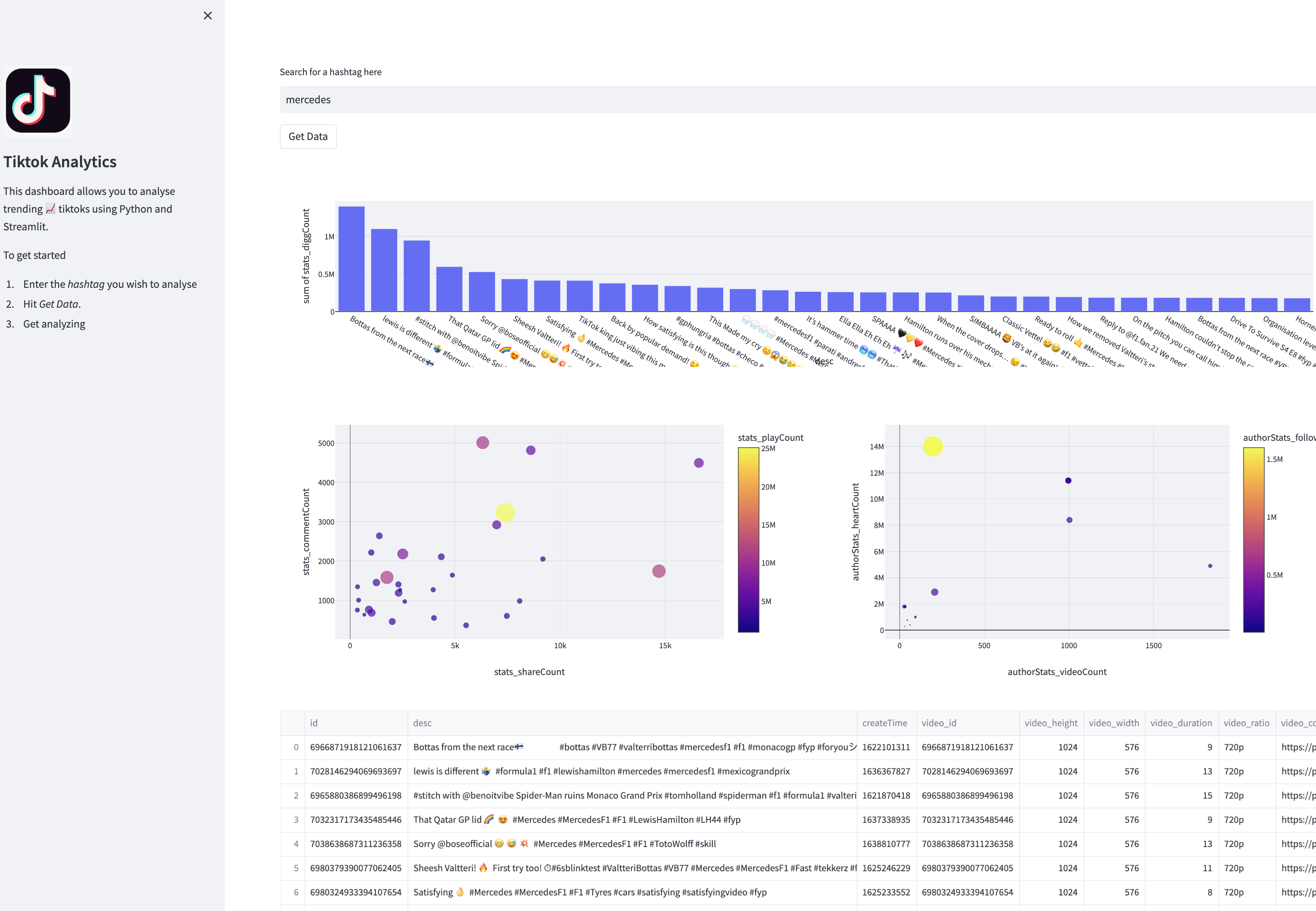
An interactive dashboard that analyses trending videos
- Scraped Tiktok data using Tiktok API
- Built an ETL pipeline to process the data into the desirable format to ingest into streamlit application
- Built an interactive Dashboard that allows user to input any hashtag and generates analytics based on the input
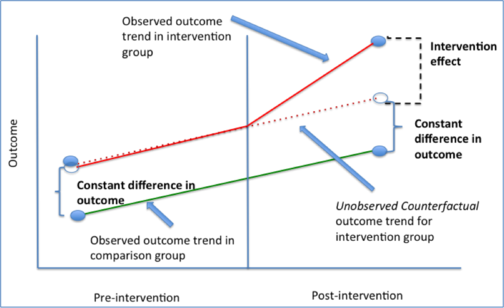
Determine the effectiveness of a campaign or product feature
- Developed a quasi-experimental system that models the performance of a campaign
- Built on Flask and deployed on AWS
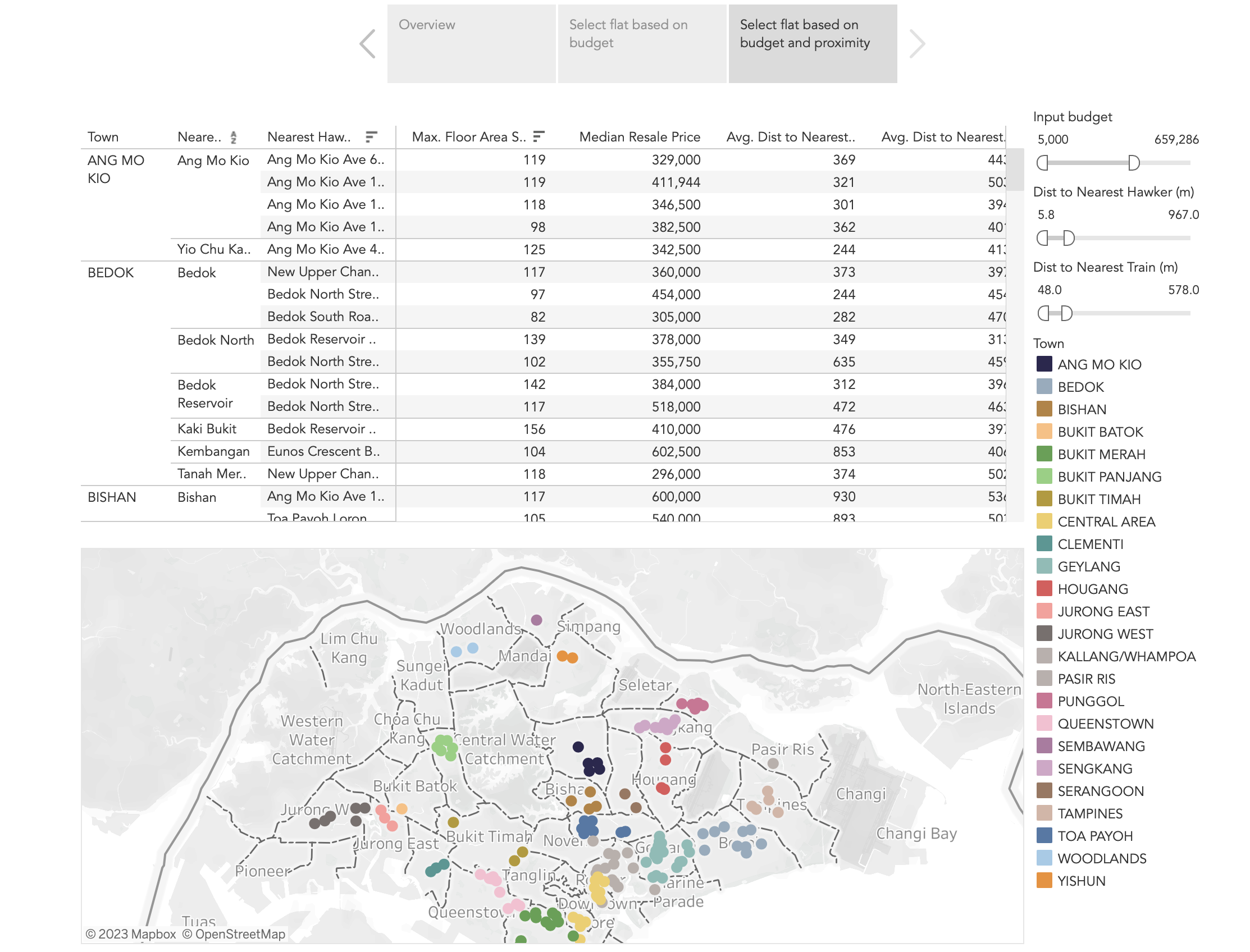
Predict housing price and visualise nearest MRT/Hawkers based on budget input
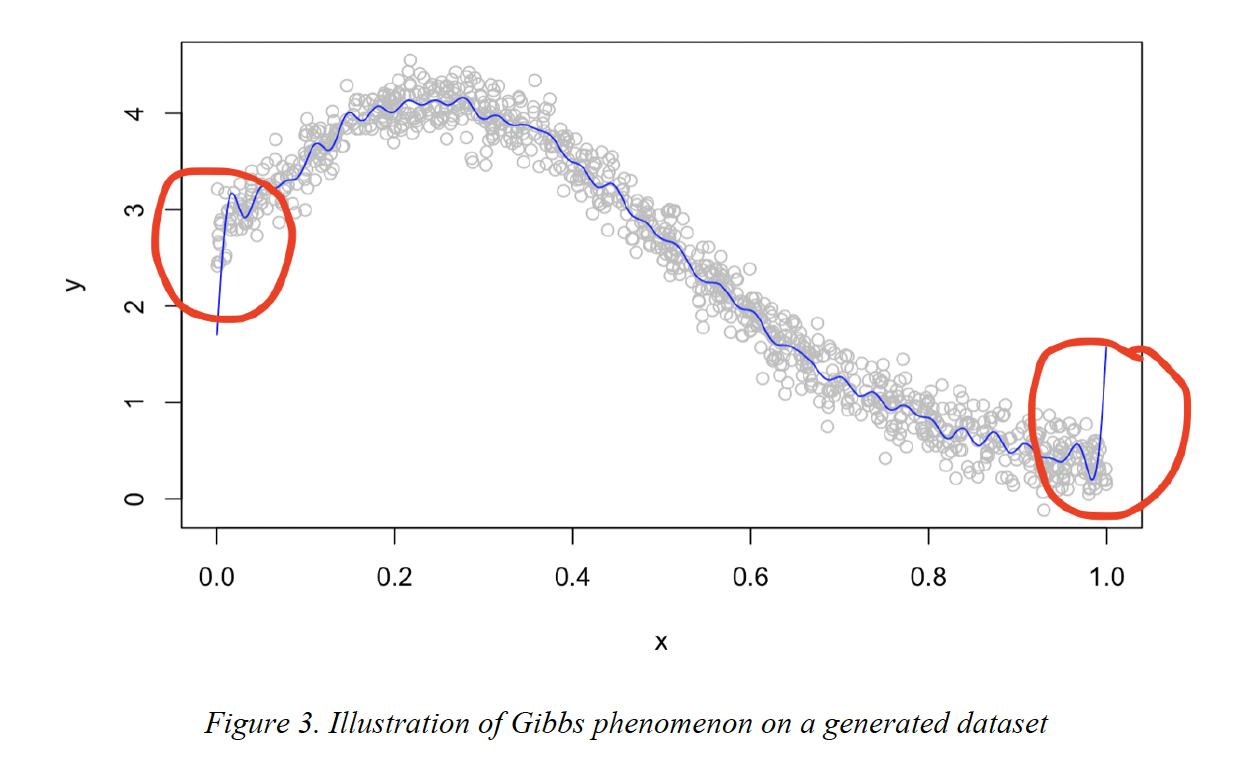
ST4199 Honours Thesis in Statistics at NUS
- Proved how Fourier Extension method outperformed other nonparametric methods in regression estimation
- Used Signal-to-Noise Ratio to generate Variance
- Simulated data using R
- Thesis Grade: A+
Skills
Languages and Databases
 R
R
 HTML5
HTML5
 CSS3
CSS3
Libraries
 scrapy
scrapy

ETL Tools
Frameworks
 Streamlit
Streamlit
 nodeJS
nodeJS
Others
 Git
Git
 AWS
AWS
 Heroku
Heroku
Certificates


Education
National University of Singapore (NUS)
Singapore
Degree: Bachelor of Science (Honours) in Statistics
- Machine Learning
- Probability Theory
- Categorical Data Analysis
- Monte Carlo simulation
- Experimental Design
Relevant Courseworks: